A WeShop-grounded essay on AI models, virtual try-on, e-commerce photography, and why usefulness arrives before perfect control.
围绕 WeShop、AI 模特、虚拟试衣和电商商拍,讨论生成式 AI 在真实电商工作流里的可用性边界。
English edition adapted for native English readers; Chinese text follows the original Zhihu source.英文版按英文读者习惯重写整理,中文版保留知乎原文。
This answer has changed as the product changed. When I first wrote it, the honest conclusion was: diffusion models could already produce impressive images, but they were still far from a foolproof e-commerce workflow. Since then, we have turned a lot of that exploration into WeShop, including a commercial Virtual Try-On system rather than just a demo.
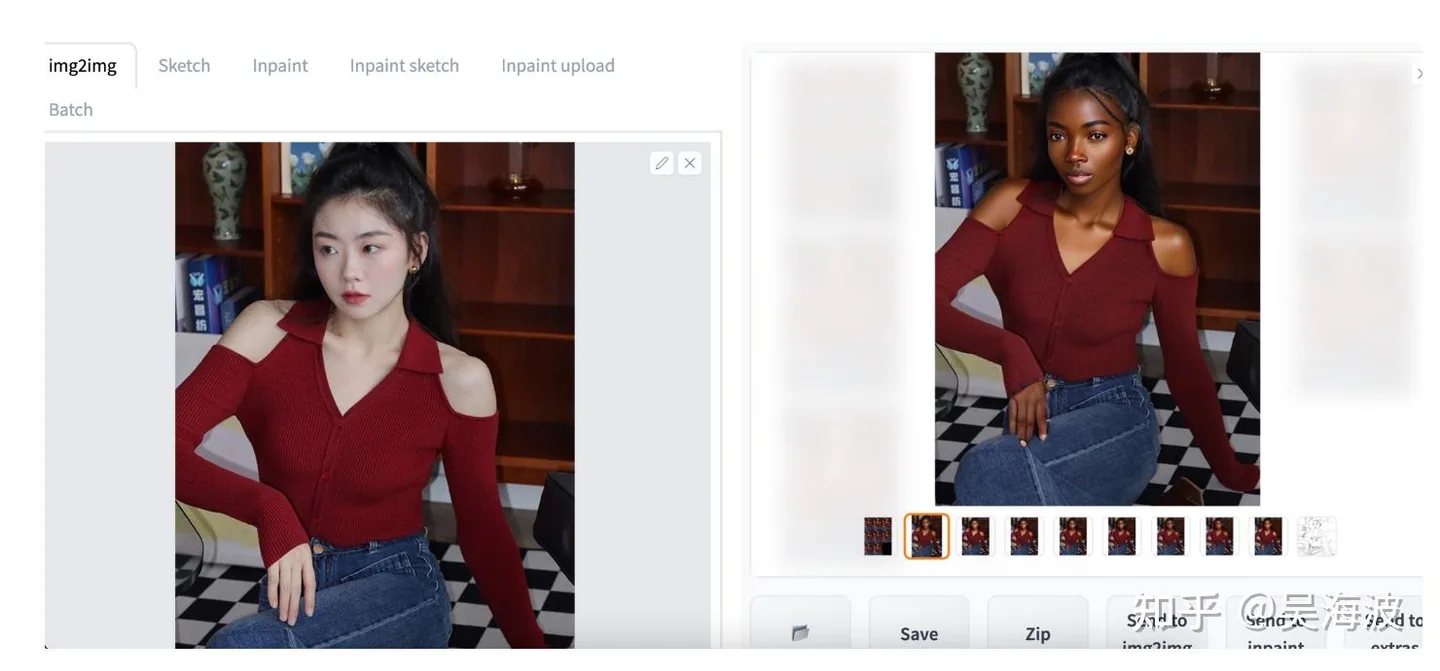
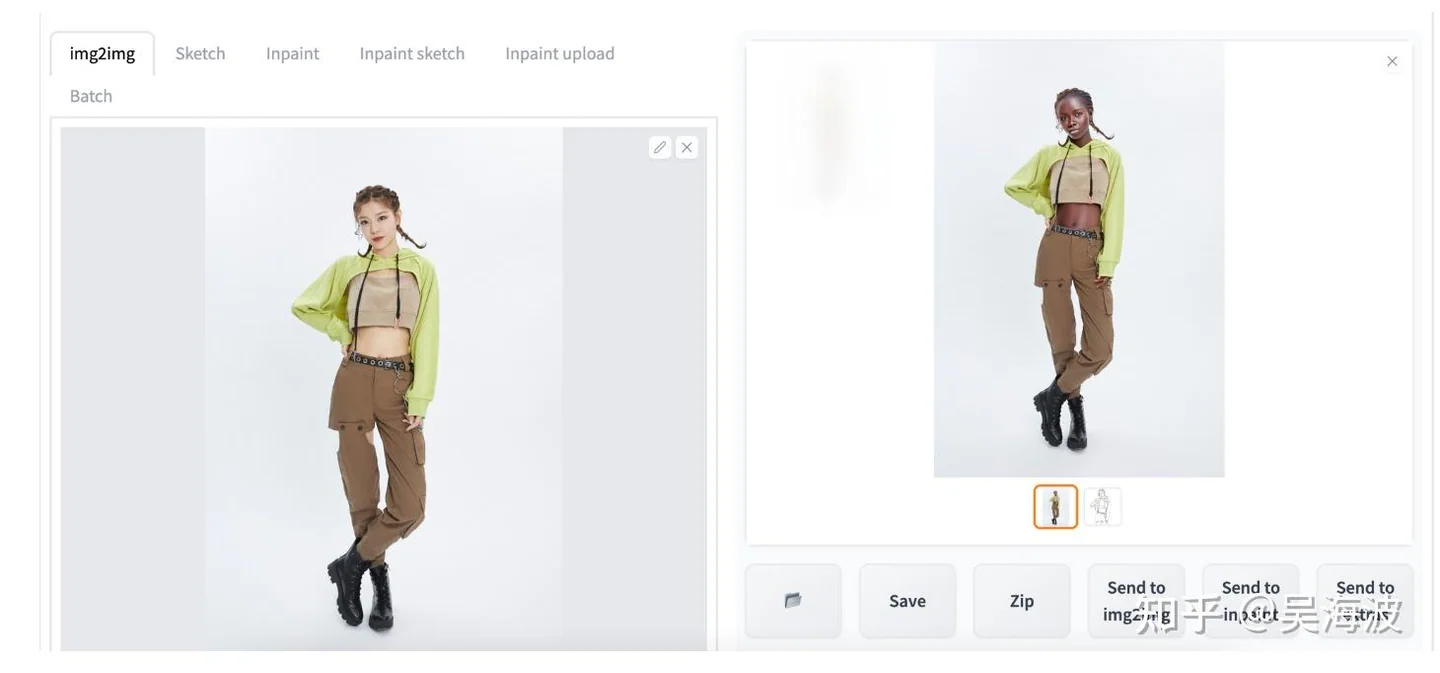
The current WeShop workflow can change faces, backgrounds, poses, and even rotate a garment presentation. You can try the demo on Hugging Face, or use the commercial product and API through WeShop.
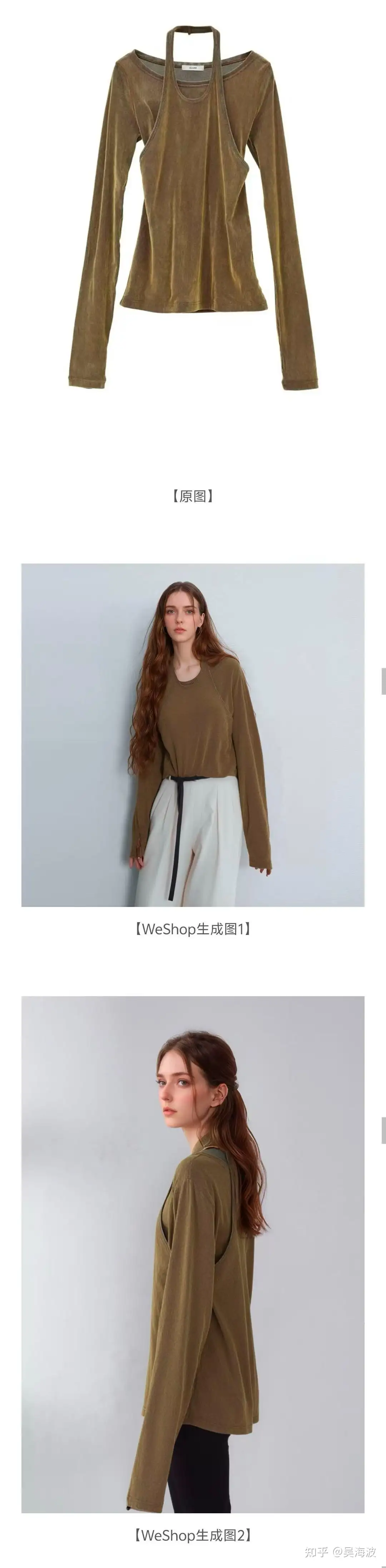
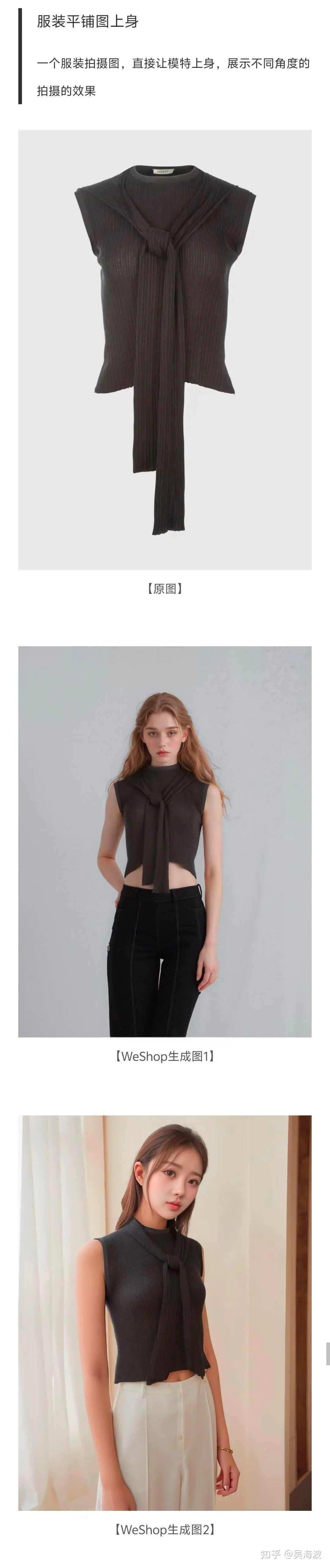
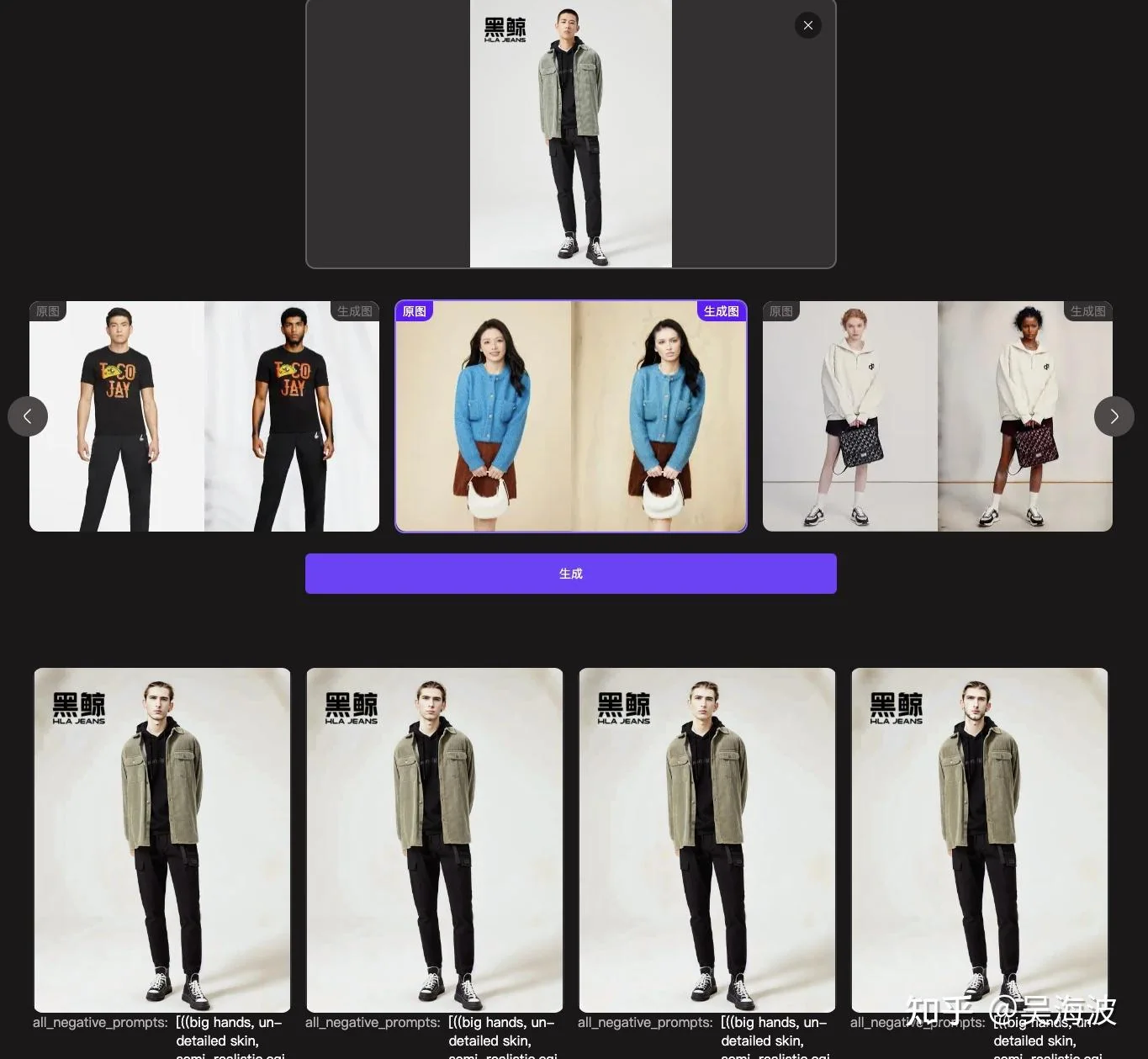
Examples from the WeShop virtual try-on workflow. WeShop product workflow example 1 from the original Zhihu answer. WeShop product workflow example 2 from the original Zhihu answer. WeShop product workflow example 3 from the original Zhihu answer. WeShop product workflow example 4 from the original Zhihu answer. WeShop product workflow example 5 from the original Zhihu answer. WeShop product workflow example 6 from the original Zhihu answer.
The important problem is not whether the image looks good once
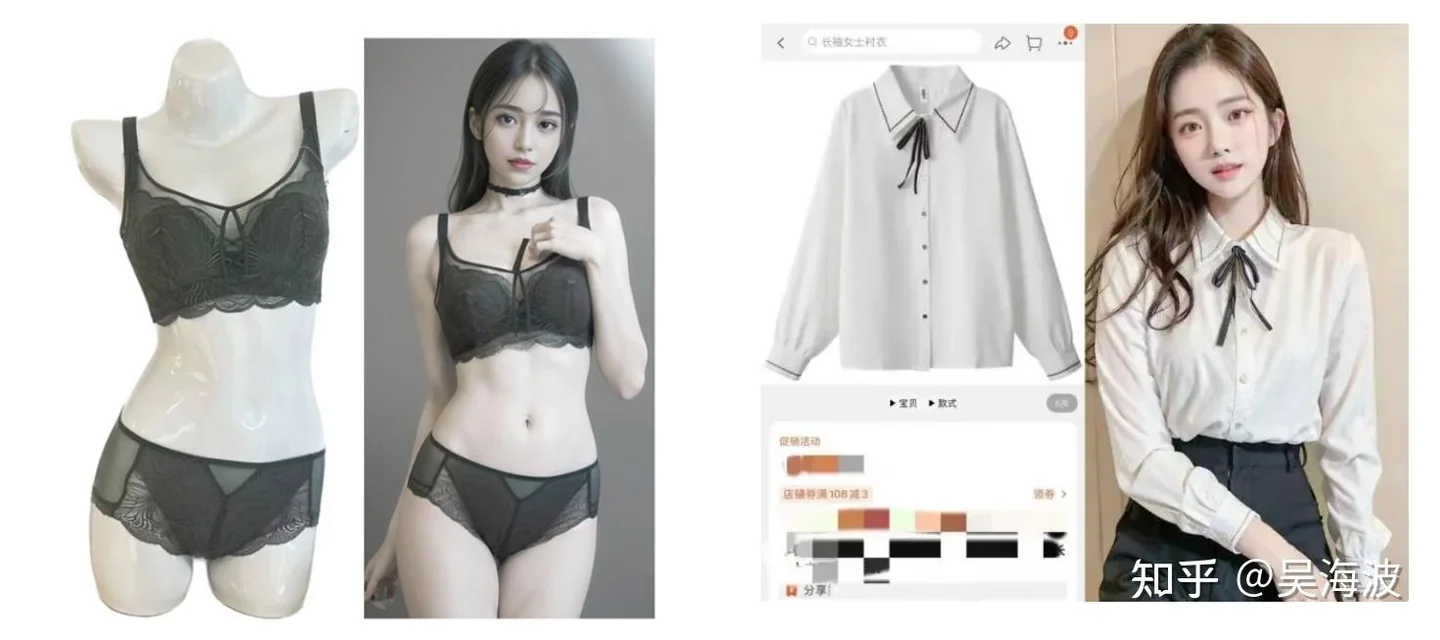
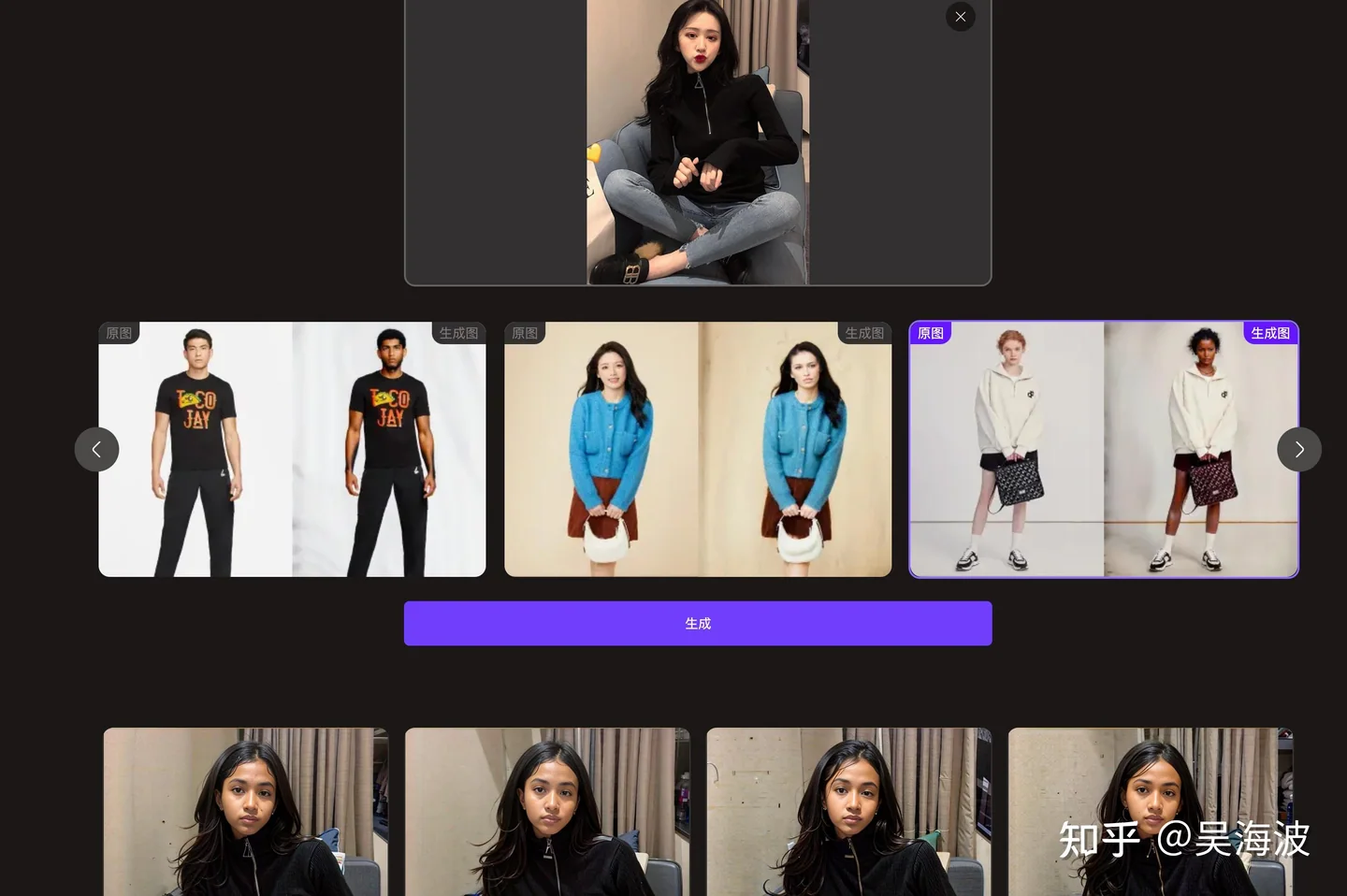
E-commerce is not a purely digital scenario. A product photo is connected to fulfillment, consumer trust, returns, and long-term brand credibility. If an AI image changes the product detail, the image may look beautiful but still hurt the buyer experience. That is why the hardest part is not generating a good-looking model. It is preserving the actual product.
This is also where many early demos became misleading. A few screenshots could make the technology look ready, but a merchant needs repeatable control: keep the garment, change the model, change the scene, keep the SKU reliable, and do it at scale.
Early WeShop e-commerce generation case 1. Early WeShop e-commerce generation case 2. Early WeShop e-commerce generation case 3. Early WeShop e-commerce generation case 4. Early WeShop e-commerce generation case 5. Early WeShop e-commerce generation case 6. Early WeShop e-commerce generation case 7. Early WeShop e-commerce generation case 8. Early WeShop e-commerce generation case 9. Early WeShop e-commerce generation case 10. Early WeShop e-commerce generation case 11. Early WeShop e-commerce generation case 12. Early WeShop e-commerce generation case 13. Early WeShop e-commerce generation case 14. Early WeShop e-commerce generation case 15. Early WeShop e-commerce generation case 16. Early WeShop e-commerce generation case 17.
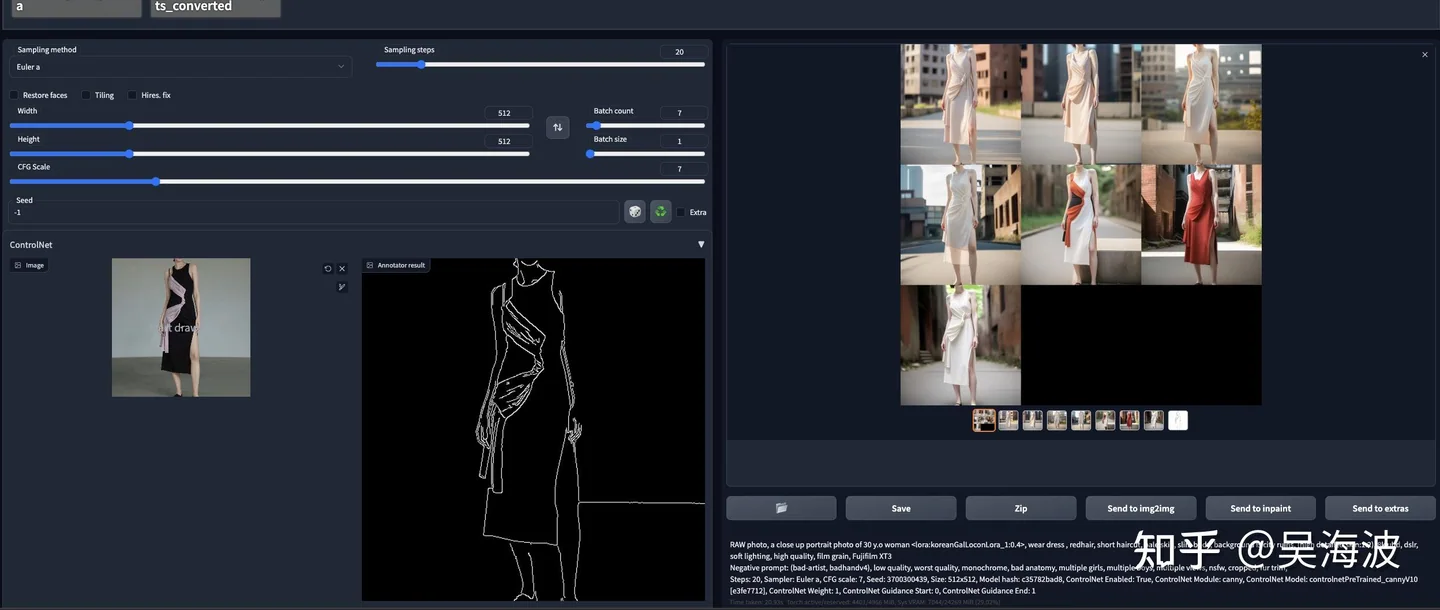
The technical routes we tried
Midjourney was polished but too closed for this use case. Stable Diffusion WebUI was much more useful because it exposed the workflow and had an active ecosystem. DreamBooth and LoRA were helpful for injecting a specific person, product, or style into generation, but product details were still fragile. LoRA could learn that a piece of lingerie had patterns, for example, while still losing the structure of the lower band.
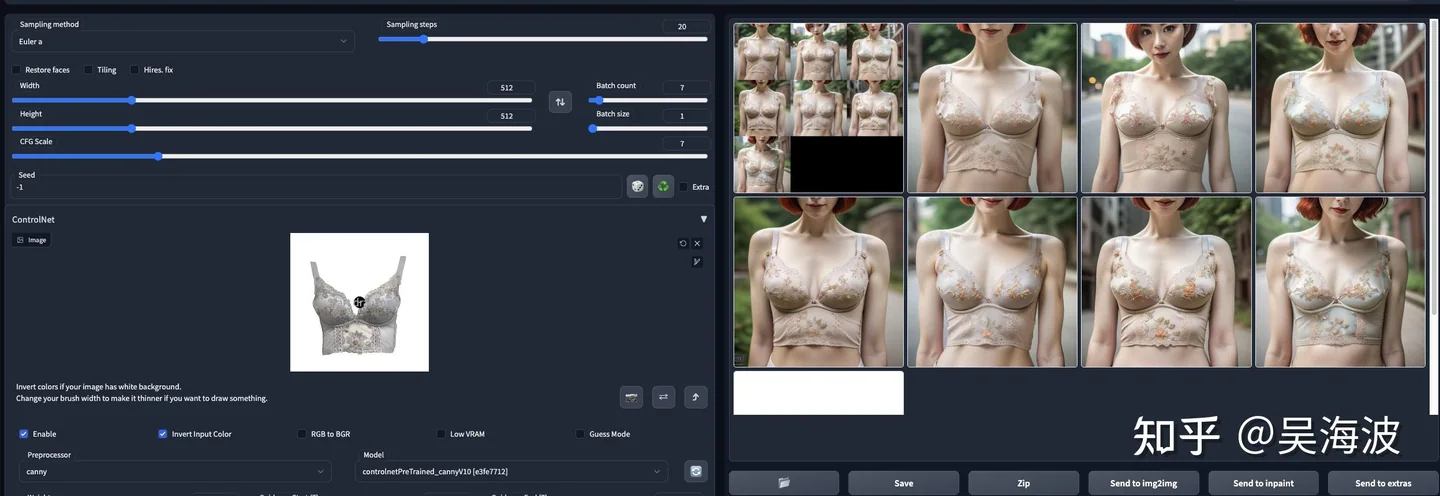
ControlNet improved structure preservation. Inpainting made the model-replacement path more realistic because we could keep the original product image and only change the model. But inpainting introduced another product problem: masks, stages, uncertainty, and debugging cost. It was powerful for studios, but too complicated for a normal merchant.
We also looked at the image-editing literature: ControlNet, Prompt-to-Prompt, Null-text Inversion, Pix2Pix-Zero, InstructPix2Pix, SDEdit, Composer, and related work. Some of these directions were promising, but e-commerce has its own instruction distribution. A model trained on general editing instructions does not automatically understand what a merchant means by “keep the collar”, “do not change the strap”, or “make this red dress green without changing the cut”.
Technical experiment from the original answer, case 1. Technical experiment from the original answer, case 2. Technical experiment from the original answer, case 3. Technical experiment from the original answer, case 4. Technical experiment from the original answer, case 5. Technical experiment from the original answer, case 6. Technical experiment from the original answer, case 7. Technical experiment from the original answer, case 8.
Productization means narrowing freedom
A raw generation interface gives users freedom, but it also gives them too many ways to fail. For WeShop, we started to design templates: common scenes, parameter sets, and workflows that compress the best practices we discovered through repeated testing. This sacrifices some creative freedom, but it makes the result more controllable.
Template and demo output from the original answer, case 1. Template and demo output from the original answer, case 2. Template and demo output from the original answer, case 3. Template and demo output from the original answer, case 4. Template and demo output from the original answer, case 5.
That is the pattern I keep seeing in AI applications: early technology expands the possibility space, while product work narrows that space into something repeatable, legible, and safe enough for real users.
The business window
Even an imperfect intermediate product can move an industry forward. Cross-border sellers, apparel manufacturers, wholesalers, and small brands all face real production costs. If AI can reduce part of the photo-shooting cost while preserving enough trust, it is already useful.
But the long-term value will not come from one more image-generation demo. It will come from workflow depth: product detail preservation, model consistency, background control, QA, API delivery, data accumulation, and the ability to serve real merchants repeatedly.