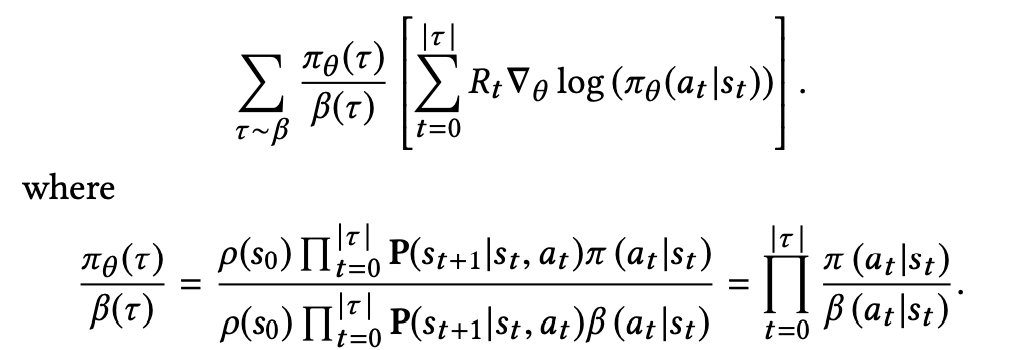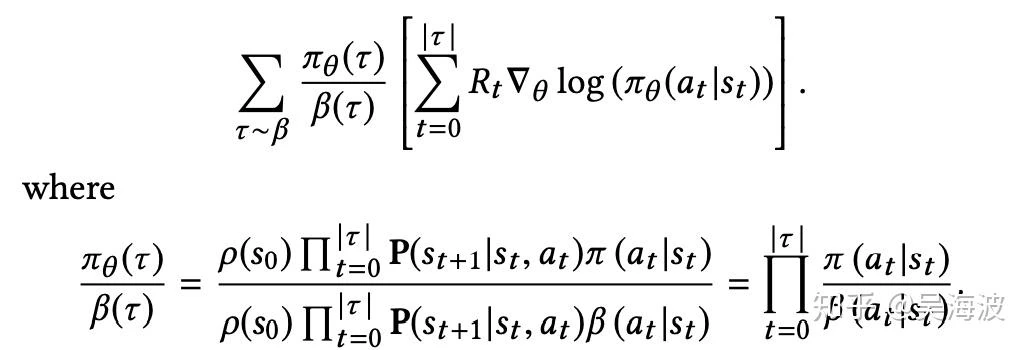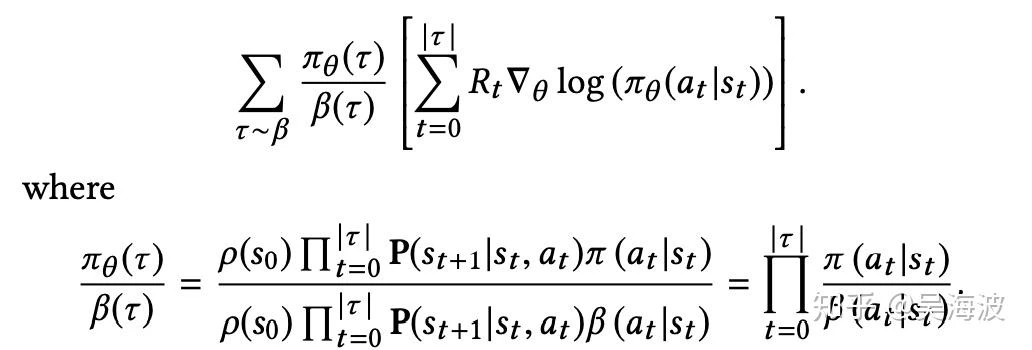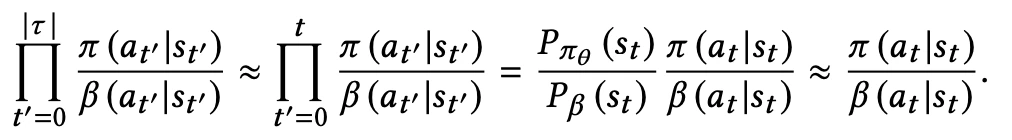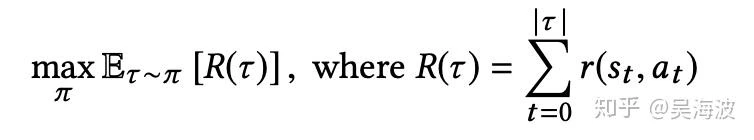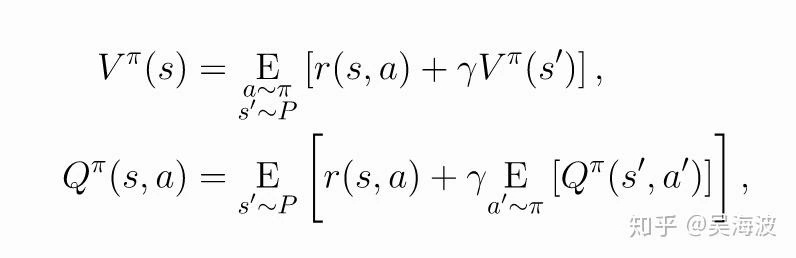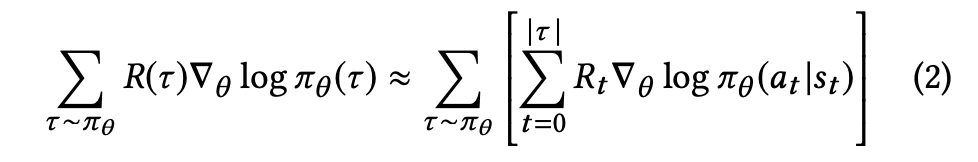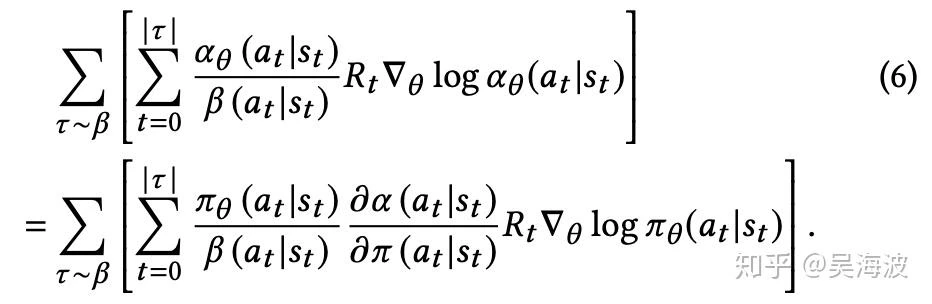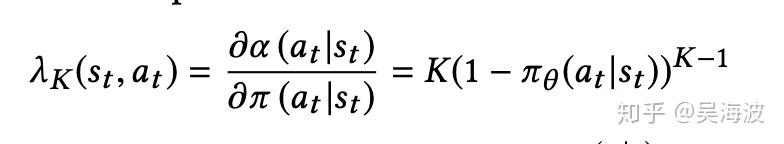English edition adapted for native English readers; Chinese text follows the original Zhihu source.英文版按英文读者习惯重写整理,中文版保留知乎原文。
Around that time, people in the industry started circulating the claim that YouTube had successfully applied reinforcement learning to recommendation and had achieved one of its most significant online gains in years. Two papers were especially worth reading: Top-K Off-Policy Correction for a REINFORCE Recommender System and Reinforcement Learning for Slate-based Recommender Systems.
One of the paper diagrams discussed in the original Zhihu answer.
Why recommendation is tempting for RL
A recommendation system is not just trying to predict the next click. It is shaping a sequence of user experiences. A short-term click may reduce long-term satisfaction; repeated similar content may raise immediate engagement while damaging exploration; and the value of one item often depends on what else appears around it. These are exactly the kinds of problems that make reinforcement learning attractive.
Challenges of applying reinforcement learning to recommender systems.
But recommendation is also a hard RL environment. The action space is enormous, the reward is delayed and noisy, online exploration is expensive, and most teams only have logs generated by an old behavior policy. You cannot simply take a textbook RL algorithm and plug it into a production recommender.
Off-policy correction figure 1 from the original answer. Off-policy correction figure 2 from the original answer. Off-policy correction figure 3 from the original answer. Off-policy correction figure 4 from the original answer. Off-policy correction figure 5 from the original answer. Off-policy correction figure 6 from the original answer.
The off-policy problem
YouTube’s Top-K off-policy correction work starts from a practical constraint: the training data was collected by an existing system, not by the policy you now want to learn. If you optimize REINFORCE directly on those logs, you will bias the model toward what the old system chose to expose. The paper’s core contribution is a correction method that makes this logged data more usable for learning a new ranking policy.
For a production team, the lesson is straightforward: before discussing RL, first ask how the logs were generated, what the exposure policy was, and whether your reward can be trusted. Most “RL for recommendation” failures begin before the model is trained.
The slate problem
The second paper looks at slate recommendation. In a real product, the user does not see one isolated item; the user sees a list. The value of the slate is not the sum of independent item values. Items interact with one another through position, substitution, diversity, and user attention.
The paper proposes a tractable way to reason about slate-level reward without enumerating the impossible number of all possible slates. That is important because the combinatorial action space is one of the main reasons recommender-system RL looks elegant in theory and painful in practice.
Slate recommendation figure 1 from the original answer. Slate recommendation figure 2 from the original answer. Slate recommendation figure 3 from the original answer.
What I take from it
The practical path is not to worship the word “RL”. It is to identify where a recommender is being hurt by short-term objectives, where sequence effects matter, and where logged feedback can support a safer learning loop. Sometimes that means reinforcement learning; sometimes it means bandits, better counterfactual evaluation, better reward design, or simply a more honest offline experiment.
For most teams, the hard work is still engineering and product definition: define the reward, log exposure correctly, build offline evaluation, control exploration risk, and make sure the model can actually run inside the serving system.
优化的目标都是short term reward,比如点击率、观看时长,很难对long term reward建模。 最主要的是预测用户的兴趣,但模型都是基于logged feedback训练,样本和特征极度稀疏,大量的物料没有充分展示过,同时还是有大量的新物料和新用户涌入,存在大量的bias。另外,用户的兴趣变化剧烈,行为多样性,存在很多Noise。 pigeon-hole:在短期目标下,容易不停的给用户推荐已有的偏好。在另一面,当新用户或者无行为用户来的时候,会更倾向于用大爆款去承接。 RL应用在推荐的挑战
看slide
RL 在推荐场景中的挑战。
extremely large action space:many millions of items to recommend.如果要考虑真实场景是给用户看一屏的物料,则更夸张,是一个排列组合问题。 由于是动态环境,无法确认给用户看一个没有看过的物料,用户的反馈会是什么,所以无法有效模拟,训练难度增加。 本质上都要预估user latent state,但存在大量的unobersever样本和noise,预估很困难,这个问题在RL和其他场景中共存。 long term reward难以建模,且long/short term reward。tradeoff due to user state estimate error。 旅程开始
• S: a continuous state space describing the user states; • A: a discrete action space, containing items available for recommendation; • P : S × A × S → R is the state transition probability; • R : S × A → R is the reward function, where r(s, a) is the immediate reward obtained by performing action a at user state s;
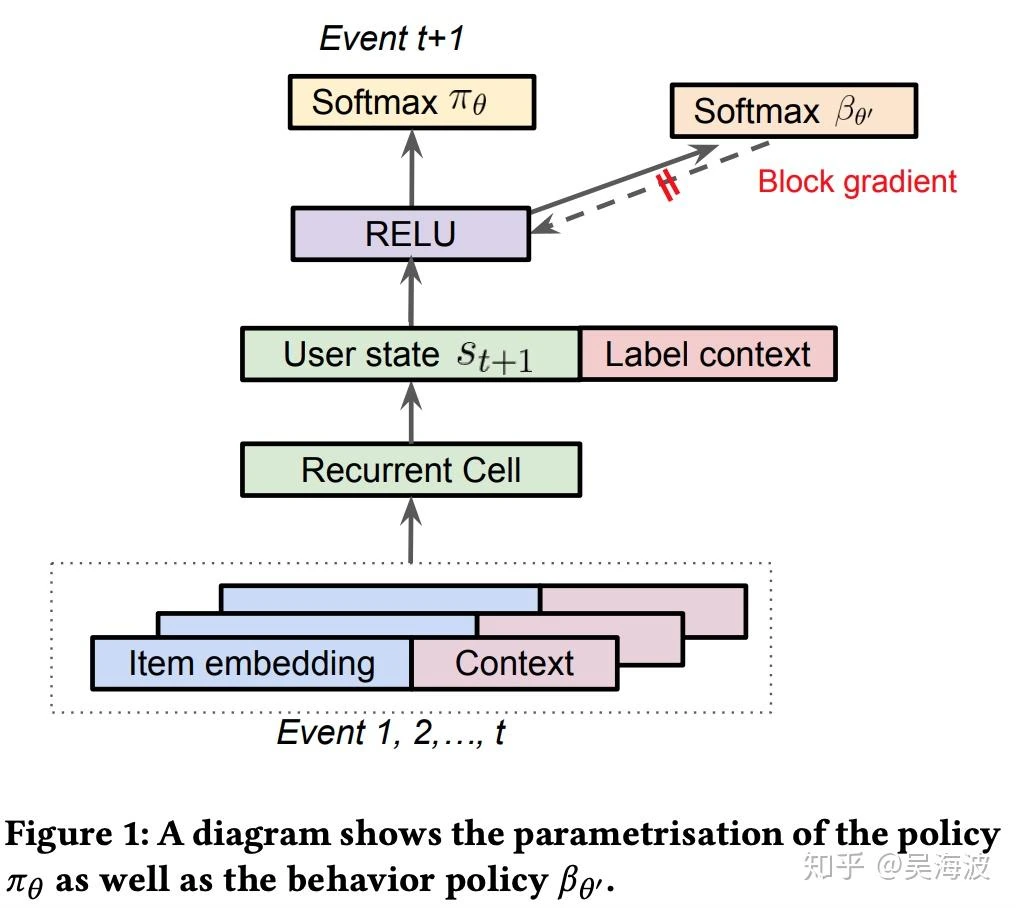
In particular, the fact that we collect data with a periodicity of several hours and compute many policy parameter updates before deploying a new version of the policy in production implies that the set of trajectories we employ to estimate the policy gradient is generated by a different policy. Moreover, we learn from batched feedback collected by other recommenders as well, which follow drastically different policies. A naive policy gradient estimator is no longer unbiased as the gradient in Equation (2) requires sampling trajectories from the updated policy πθ while the trajectories we collected were drawn from a combination of historical policies β.
(1) While the main policy πθ is effectively trained using a weighted softmax to take into account of long term reward, the behavior policy head βθ′ is trained using only the state-action pairs; (2) While the main policy head πθ is trained using only items on the trajectory with non-zero reward 3, the behavior policy βθ′ is trained using all of the items on the trajectory to avoid introducing bias in the β estimate.
The immediate reward r is designed to reflect different user activities; videos that are recommended but not clicked receive zero reward. The long term reward R is aggregated over a time horizon of 4–10 hours.
主流的个性化推荐应用,都是一次性给用户看一屏的物料,即给出的是一个列表。而目前主流的个性化技术,以ctr预估为例,主要集中在预估单个物料的ctr,和真实场景有一定的gap。当然,了解过learning to rank的同学,早就听过pointwise、pairwise、listwise,其中listwise就是在解决这个问题。
这篇写的有点长,但就算如此,看了本文也很难让大家一下子就熟悉了RL,希望能起到抛砖引玉的作用吧。从实践角度讲,比较可惜的是long term reward的建模、tensorflow在训练大规模RL应用时的问题讲的很少。最后,不知道youtube有没有在mutil-task上深入实践过,论文[2]中也提到它在long term上能做一些事情,和RL的对比是怎么样的。
参考
[1] Top-K Off-Policy Correction for a REINFORCE Recommender System
[2] Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology*