Recently, Memex was recommended by a few overseas AI bloggers.
One Instagram post got 16,000 likes. The project picked up some GitHub stars as well, though it was still far from “going viral.”
The funny part is that at first we had no idea what had happened.
GitHub analytics only showed a few vague referrers. We searched X, TikTok, and YouTube ourselves but still could not find the real source. In the end I asked ChatGPT to search whether anyone overseas had mentioned Memex recently, and that was how I found those recommendation posts.
For an AI project, discovering the source of growth through ChatGPT is, in a way, very GEO.
https://www.instagram.com/reels/DZFafmFNwMp/

Memex is an open-source, local-first AI journal. You can drop in fragments of life — text, images, voice, screenshots — and let AI organize them into your own memory.
But this piece is not mainly about product features. I want to record how a small open-source project with no resources, no paid promotion, and no partnerships slowly became visible to other people.
The earliest starting point was not the product itself, but our research into Claude Code.
We realized early that agents do not necessarily need complex databases, indexes, or RAG from day one. In many cases, if information is organized as markdown and paired with basic bash commands such as find, grep, and file reads and writes, an agent can already do very powerful things.
That judgment later became the underlying intuition behind Memex’s early architecture.
We were not building a traditional diary app. We wanted to build a “file system for personal memory”: records can be fragmented, organization can be handed to agents, and structure can grow gradually over time.
Of course, when we first released it, almost nothing happened. For example, I wrote a product-thinking piece titled “We Built Something About ‘Recording Yourself,’ Then Decided to Open Source It,” and it barely got any traffic.
So we wrote bits of thinking on Xiaohongshu and Zhihu, kept improving the README, built the website, shipped to the App Store and Google Play, and kept using and improving the product ourselves. That stage was slow, and it was easy to wonder whether we were the only ones who found the idea interesting.
The first wave of cold-start growth actually came from a comment.
A while ago, Karpathy published a gist called LLM Wiki. The rough idea was to use LLMs to maintain a markdown-based personal knowledge base. Instead of the traditional RAG pattern of “retrieve only when a question is asked,” the model would continuously organize, update, and connect markdown files, allowing the knowledge base to grow by itself over time. https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
It resonated strongly with us, because it was very close to many of the ideas behind Memex.
So when we saw Karpathy’s gist, we left a serious reply in the comments and mentioned Memex.
That became our first wave of cold-start traffic.
The experience left a strong impression on me: when you have no resources, the best promotion may not be “promotion” at all, but showing up in the right conversation.
You have to have really thought about the problem and really built something, so that when others are discussing it, you can meaningfully join the conversation.
This is very close to built in public.
It is not about shouting every day that “we shipped another update.” It is about continuously exposing your judgments, iterations, and confusions. Early on, there may be almost no feedback, but those traces accumulate. When a discussion happens to intersect with your work, people can follow those traces back to you.
Later, Memex slowly crossed 100 stars.
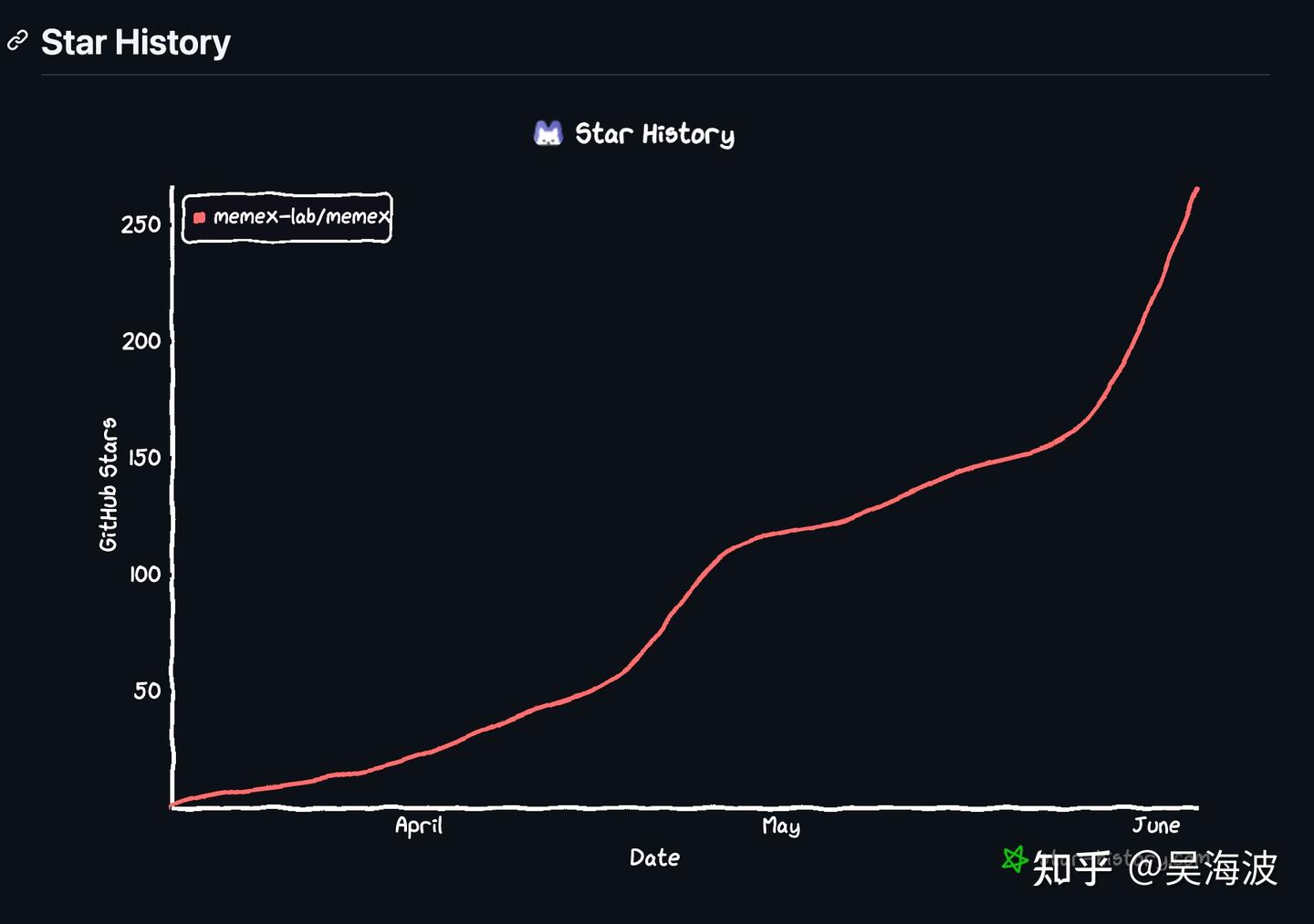
That number is not large, but for a small open-source project it felt like a faint signal: at least the thing was not completely ignored. After that point, a few smaller bloggers found us, then somewhat larger accounts reposted the project, and eventually there was that Instagram post with 16,000 likes.
So the path was actually very plain:
First, we clarified some of our own thinking. Then we built the product. Then we spoke seriously in relevant discussions. Then the first group of people came in. Then we kept iterating. Then more people happened to discover it.
There was no magical method.
This was a bootstrapped project. We had no budget, no partnerships, and no overseas channels. A lot of the work was simply slow accumulation: improving the README, adding to the website, writing on Xiaohongshu and Zhihu, shipping to the App Store and Google Play, responding to user feedback. Gradually it became a product serving users around the world.
This experience made me more certain of one thing: in this stage of AI agents, individual developers do have opportunities.
A lot of things are being re-understood. You may not have resources, but if you understand a new paradigm early enough, keep turning ideas into working products, and iterate in public, you may be discovered by others who are thinking about the same thing.
Of course, the other side is painful.
Our understanding of agents has changed quickly over the past few months. Once your understanding changes, you start seeing many awkward parts in the old product architecture. Memex is now preparing for a fairly large refactor.
That is also what I find interesting about built in public: it is not just making an outcome public, but making public how an idea changes, and how a product is pushed forward by your own new understanding.
Memex is still very early, and many parts are not good enough. But if you are interested in AI agents, local-first software, personal memory, or companionship-like products, you are welcome to visit GitHub or join the work.
Website: Memex — Open-Source AI Journal That Organizes Your Life