Background
For people who came to algorithms through deep learning, diffusion-model papers can feel unusually uncomfortable at first. Compared with many mainstream deep-learning papers, they use more mathematical tools, and in recent years the work with heavier math has often been less visible outside the research community.
If formulas do not scare you away, I would start with Understanding Diffusion Models: A Unified Perspective. Among the materials I read, it assumes the least background and rarely forces the reader to search for extra context. Then read What are Diffusion Models? and Generative Modeling by Estimating Gradients of the Data Distribution. If you prefer code first, Hugging Face's The Annotated Diffusion Model is a good PyTorch entry point.
This guide is not a shortcut. It is a set of notes meant to reduce the initial discomfort and help more people build the right basic concepts.
The basic problem
Generative modeling starts from a dataset drawn from some underlying distribution. If we can fit that data distribution, we can synthesize new samples by sampling from it. In plain language: the images we observe in the real world can be viewed as data from a distribution p(x). If we learn that distribution well enough, we can generate new images from it.
In reality, p(x) is complex. From my learning experience, VAE is the easiest entry point for understanding diffusion models.
Allegory of the cave

The allegory describes people who can only see two-dimensional shadows on a cave wall, while the shadows are projections of three-dimensional objects outside the cave. The point is that the data we observe may be determined by another distribution in a higher or latent space.
More formally, there may be a latent variable z that determines the distribution of the observed data x. Because high-dimensional distributions are hard, z is usually lower-dimensional than x.
The VAE route
A VAE uses two networks: an encoder that maps observed data x into a latent variable z, and a decoder that maps sampled z back to x. In practice, the model trains two parameter sets, often written as p_theta(x|z) and q_phi(z|x).
The VAE objective follows a likelihood-based route. It maximizes the probability of observed data, using the evidence lower bound, or ELBO, as a tractable lower bound.
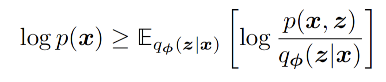
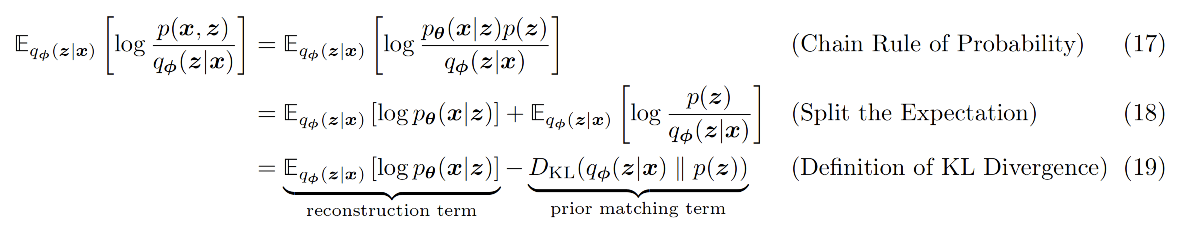
The two terms in the objective have intuitive meanings: the decoder should reconstruct the image well, and the encoder distribution should stay close to the assumed prior p(z).
The problem is that ELBO is only a lower bound. A loose lower bound is still a lower bound, but it may not produce good samples. VAE also depends on choices such as Gaussian families, reparameterization, and KL divergence because sampling would otherwise break gradient flow.
In short, VAE makes several assumptions to become trainable, and those assumptions limit its ceiling.
The core idea of diffusion models
Diffusion models can be seen as a successful attempt to reduce the difficulty of the VAE-style problem. Instead of learning both encoder and decoder at once, diffusion fixes the forward process.
If you repeatedly add Gaussian noise to an image, after enough steps it becomes nearly pure Gaussian noise.

Compared with VAE, the encoder-like forward process is written by us in advance. It does not need to be learned. The model focuses on learning the reverse process: how to reconstruct data step by step from noise.
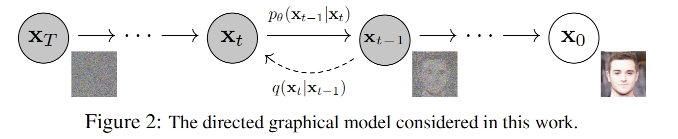
Because the forward process is stepwise, the reverse process can also be stepwise. The decoder no longer needs to generate the whole image in one jump. It can restore the image little by little, which makes the problem much easier.
Understanding it as a deep-learning algorithm
- Forward diffusion: take an original image and turn it into Gaussian noise over T steps, with the noise schedule fixed in advance.
- Reverse diffusion: train a neural network to learn the distribution that gradually restores the noise image back toward the original image.
After a series of derivations, the ELBO for diffusion models can be written in a complicated form, then simplified into a very clean objective.
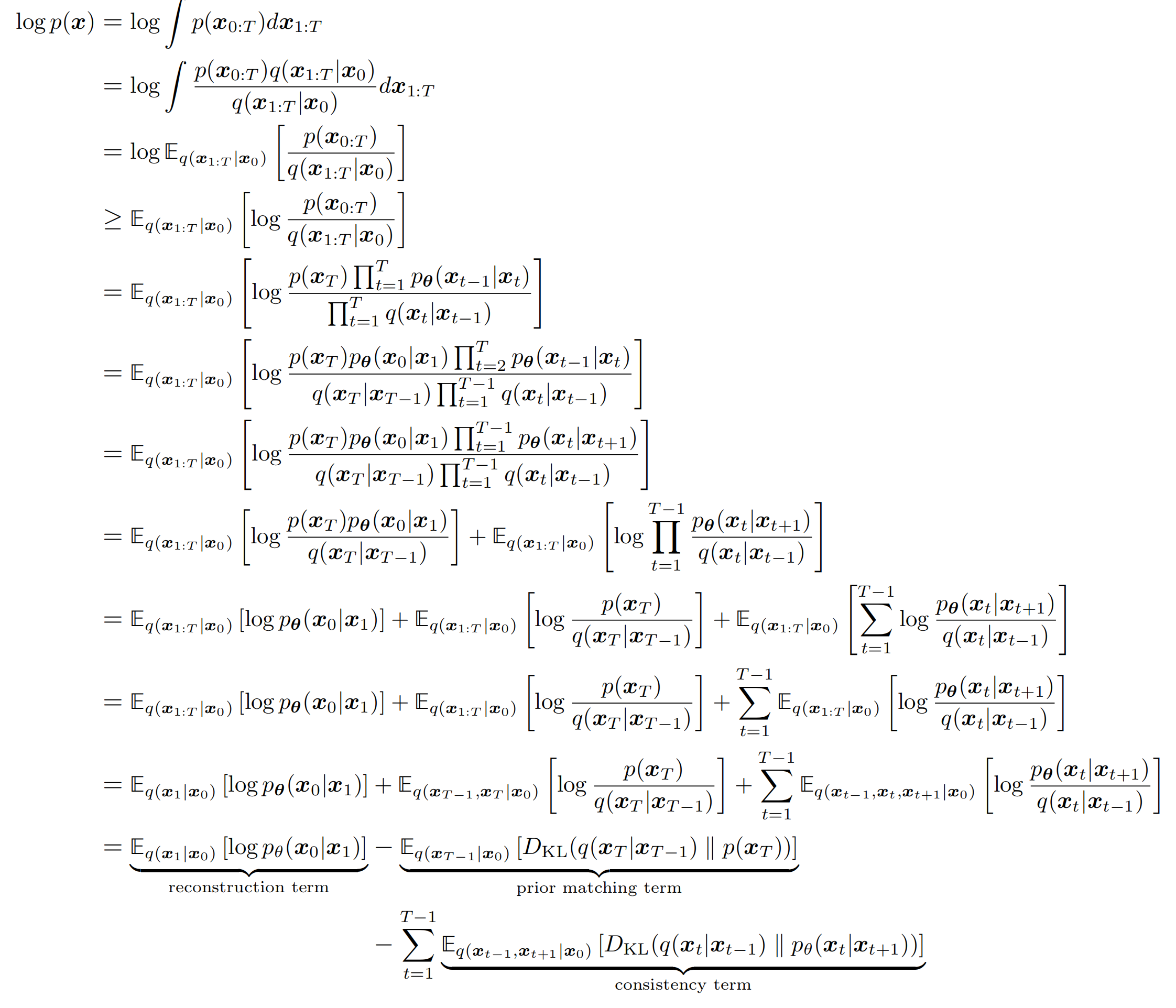
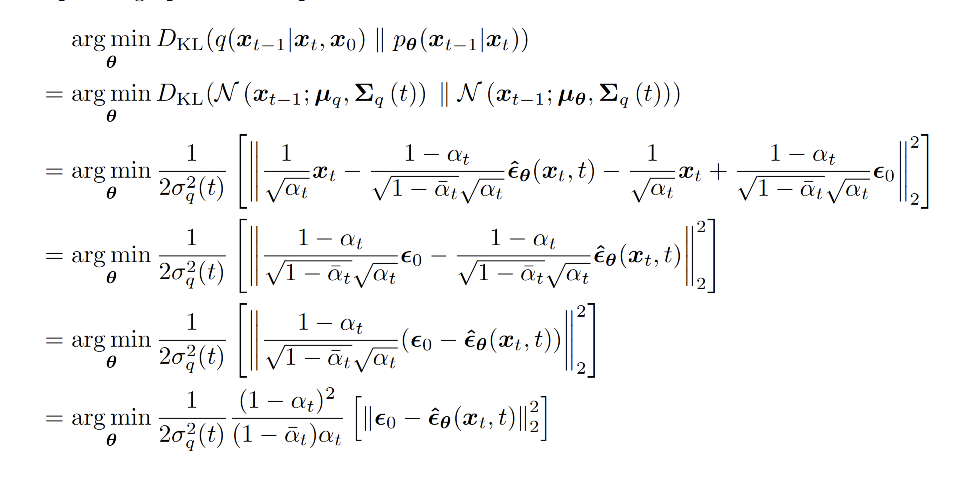
The simplified view is: at each step, train the model to predict the noise that was added. The model does not directly learn the full data distribution. It learns the noise distribution added during the forward process.
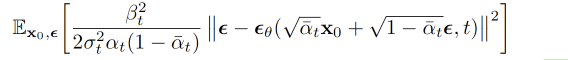
Most mainstream implementations use U-Net-like structures. The architecture matters, but this guide focuses on the basic process rather than the network-design details.
Training

- Start from x_0, an original image from the training set.
- Sample a timestep t. Thanks to the math, training does not need to simulate every step from 0 to t each time.
- Sample Gaussian noise epsilon.
- Feed x_0, epsilon, and t into the model, then train it to predict the noise.
The key trick is that x_t can be written directly from x_0 and a sampled noise term using reparameterization. That makes training much more efficient because any t can be sampled directly.
Sampling

Sampling starts from Gaussian noise and walks backward from T to 0. At each step, the model predicts the noise component and uses it to recover the previous image state. Repeating this process gradually denoises the image.
Summary
This guide only covers the basic concepts. It does not cover the many later developments or unresolved problems in diffusion models. The field has moved quickly, and there is a large body of work worth exploring.
The goal is to make the first encounter less painful: understand the generative-model problem, use VAE to motivate the latent-variable view, then see diffusion as a fixed noising process plus a learned denoising process.
