This piece came from a period of intense discussion around large language models. Rather than write another model-centric explainer, I wanted to look at ChatGPT from the position I knew better: someone who had worked across deep learning, engineering, and internet products.
Large language models did not appear out of nowhere. To understand ChatGPT, you have to trace roughly a decade of deep-learning progress, especially in natural language processing. But for application builders, the more important question is not only how the model works. It is why the product suddenly works.
Start with the strange phenomenon of emergence
Deep learning has always been criticized for weak theory. But in the history of science, useful applications often arrived before complete theory. Major unexplained phenomena are sometimes the opening for new theory.
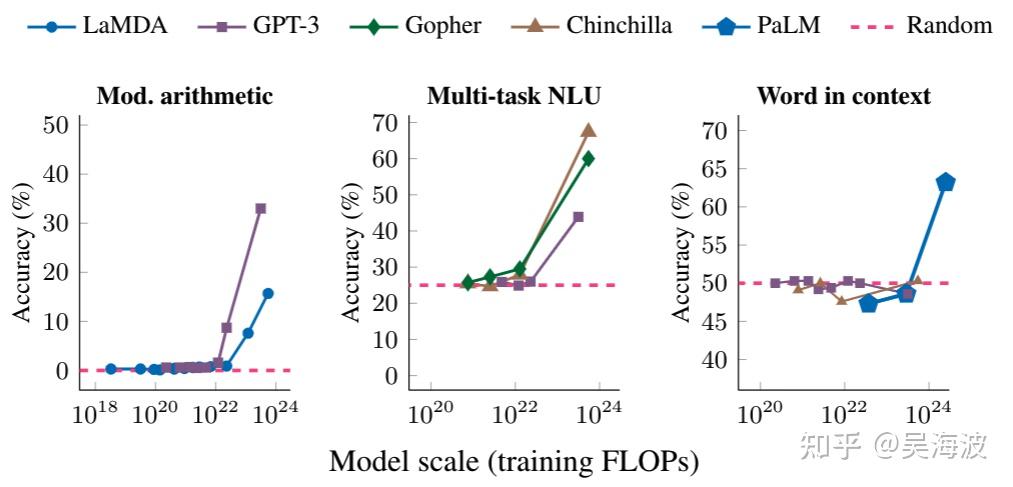
The mysterious part of LLMs is emergent ability. Researchers still do not have a fully satisfying explanation for why performance can jump sharply after scale passes certain thresholds. If we understood this well, it might even reshape the old debate between statistical and symbolic views of intelligence.
LeCun's criticism of ChatGPT-as-AGI came from a familiar position: statistical methods should not be enough for general intelligence. Yet emergence hangs over that argument like a cloud. If similar effects appeared in vision or multimodal systems, the implications would be much larger than a commercial race between model providers.
There are several possible explanations. Maybe our evaluation metrics are too discontinuous, and the capability is present earlier than the score suggests. Maybe some knowledge and reasoning patterns are learned incorrectly at small scale, then corrected only when the model becomes large enough. Or maybe scale really does produce a qualitative change in a sufficiently complex learned distribution.
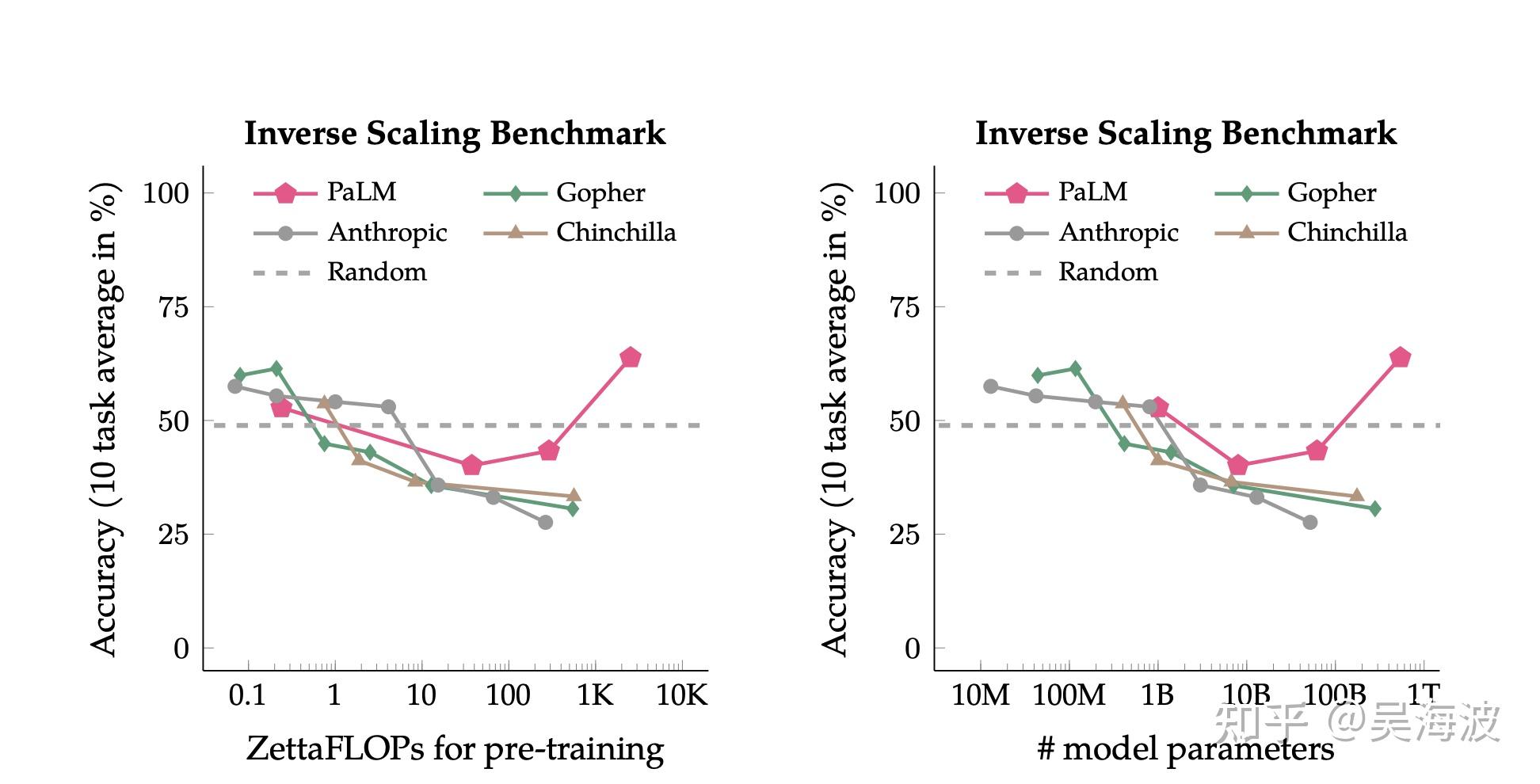
Alignment is the key to productization
Compute, data, and algorithms explain much of AI progress, but productization depends heavily on alignment. This may be one of the places where OpenAI was ahead of the industry in product judgment.
I am using “alignment” here in a practical product sense: the methods that make a model's latent capability line up with what users actually want. Prompting, in-context learning, chain-of-thought style interaction, and RLHF all belong to this broader product story.
Prompting as the UI/UX of the AI era
Many people compared prompts to a new kind of UI/UX. That comparison is useful. Prompting was not merely a research trick for matching downstream tasks to pretraining. It became a way for users to expose and steer model capabilities.
In-context learning looked at first like a way to distinguish zero-shot use from meta-learning. But later work showed something more surprising: even wrong examples sometimes did not hurt performance much, while examples from the wrong distribution did. The prompt was not simply a label. It was a context-setting interface.
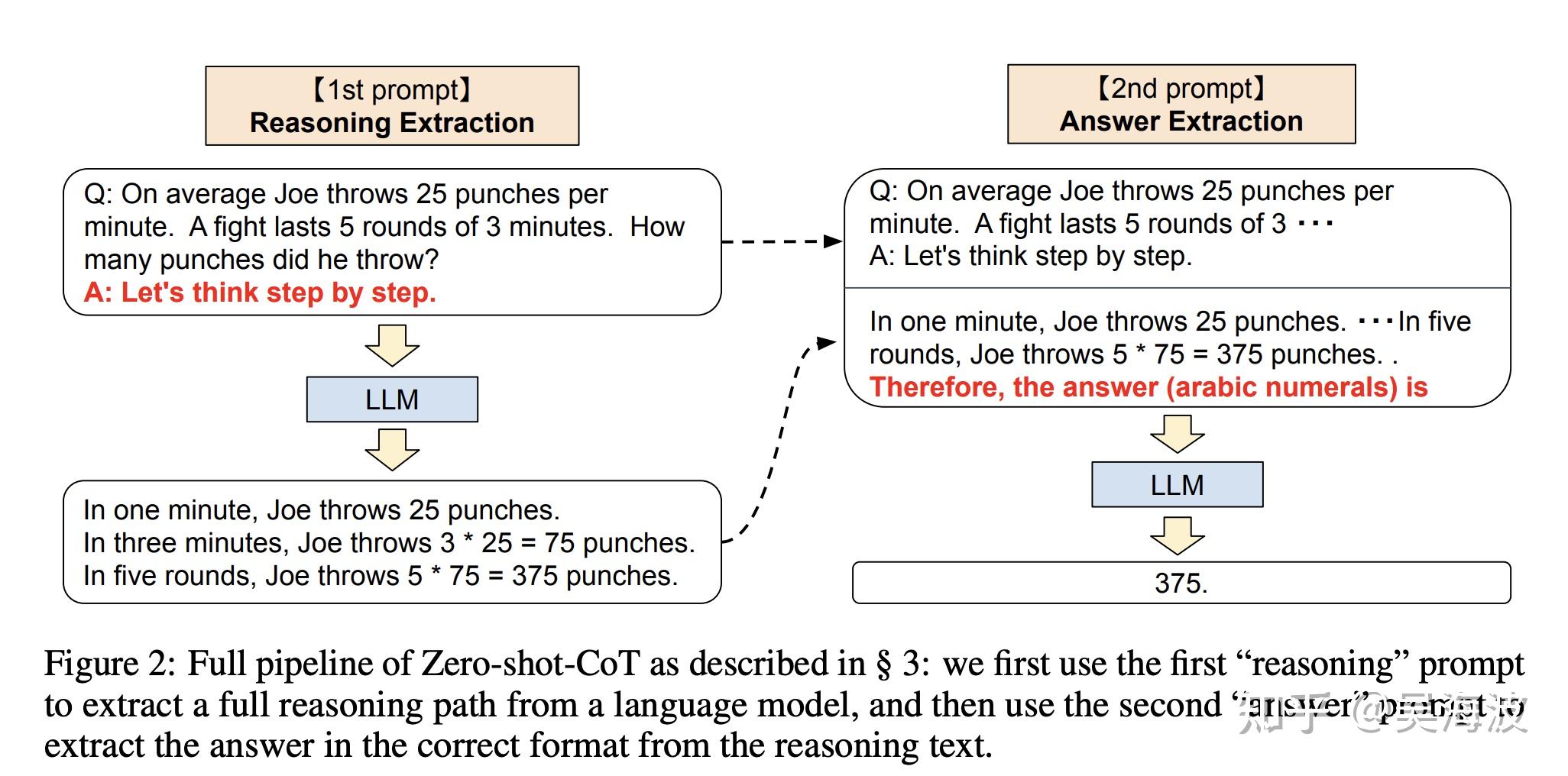
The same applies to chain-of-thought style prompting. A model that seems weak at reasoning can improve noticeably when the interaction asks it to proceed step by step. Before we understand the mechanism deeply, AI researchers often look like alchemists: trying different spells to summon capability from a system we do not fully understand.
ChatGPT found a better alignment surface: GPT-3.5 plus RLHF, wrapped in a dialogue product. That does not mean the full capability of LLMs has been unlocked. It means interaction design became part of the model's effective intelligence.
Will LLMs look like search engines or cloud computing?
One important business question is whether large models will resemble Google-style search dominance or AWS-style infrastructure competition. My intuition is closer to the AWS analogy: one company may lead, but multiple strong providers can still exist.
Search and recommendation systems did not truly understand content. They mined user behavior and distribution feedback. In the LLM era, models begin to understand and generate content itself. That weakens some old supply-side moats and changes how distribution may work.
ChatGPT was the best product at the time and had strong user feedback, but the underlying LLM technology was not locked inside OpenAI. Google and Meta also had users, talent, and infrastructure. It was reasonable to expect serious competitors.
Hallucination and external memory
ChatGPT can produce factual errors, and model training has a time boundary. In production, it can expand the capability boundary of professionals, but it cannot simply replace expertise. The model was especially strong in technical domains partly because the web contains a large amount of high-quality programming and IT material.
After GPT-3, much work studied how models store, modify, and correct knowledge. Some research viewed the transformer's feed-forward layers as a kind of key-value memory. Other work tried to update specific facts through constrained optimization without damaging unrelated knowledge.
From an energy and system-design perspective, I think LLMs should rely less on memorizing every factual detail and more on reasoning over external knowledge. Retrieval-augmented approaches, DeepMind's RETRO, vector databases, LangChain, GPTIndex, and the early new Bing all pointed in that direction.
When will multimodality really arrive?
I believe multimodal large models are a prerequisite for AGI. Humans learn in a physical world; text is already an abstraction. Vision provides stronger anchors in physical regularities, which may help models learn more fundamental concepts.
But the path is not straightforward. CLIP was useful, but more like BERT than GPT-3. ViT was promising, but the tokenization problem in vision is different from language: text tokens carry semantic structure in a way image patches do not. This is part of why diffusion models became so effective in image generation while transformer-style sequence modeling faced different constraints.
Another guess: truly large multimodal models will need sparsity. If we loosely compare parameter scale with human synapses, GPT-3 was still far smaller. Scaling further while keeping inference cost manageable likely requires sparse architectures and new infrastructure.
A new era of application innovation
Media often ask which jobs will be affected by AI. The better question may be: which ones will not? I was not fully optimistic about AGI, but the capabilities shown by ChatGPT and diffusion models were broad enough that most industries should take them seriously.
This wave changes human-computer interaction. We will see a generation of applications whose primary interface is natural language. For the first time, machines can interpret human intent with this level of detail, across multiple rounds, with each interaction shaped by context.
Think about Office, Photoshop, or video editing tools. Learning them often means learning a graphical programming language for instructing a computer. If users can express intent directly in natural language, many categories of software can be rebuilt.
That does not mean every AI application will succeed. Every technology has boundaries, and we do not yet know where they are. Many early AI apps will simply wrap an API without a durable moat. The deeper opportunities are in workflow design, alignment with user intent, and surviving long enough for the next maturity cycle.
Other questions worth tracking
- Data quality is often misunderstood. Many people still think model training mainly requires labeled data, while the NLP scaling story depended heavily on self-supervised objectives such as masked language modeling.
- Compute still matters. GPUs face physical limits too, but parallel workloads have allowed rapid growth. In the large-model era, demand for compute is obvious; the open question is whether supply costs fall as quickly as people expect.
- New optimization algorithms may matter. Some researchers, including Hinton, have long questioned whether SGD-based backpropagation is the right long-term path for intelligence.
