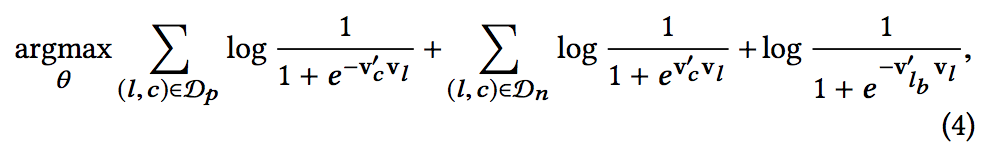English edition adapted for native English readers; Chinese text follows the original Zhihu source.英文版按英文读者习惯重写整理,中文版保留知乎原文。
Airbnb’s KDD 2018 best paper was not a flashy paper, and that is exactly why I liked it. It reminded me of Google’s Wide & Deep work: practical, grounded, and close to the kind of problems real recommender-system teams face every day.
In recommendation, embedding work is often described as if the model is the main story. In practice, the model is only one piece. The more important questions are: what behavior sequence becomes the corpus, what the embedding space is supposed to represent, how sparse IDs are handled, how the vectors are evaluated, and how the features enter online ranking.
What should the embedding represent?
In NLP, the embedding space is usually a semantic space induced by text. In e-commerce, news, travel, or other internet products, the “corpus” is usually user behavior. Clicks, bookings, purchases, favorites, skips, and rejections do not express the same kind of interest. The embedding space is therefore not universal; it is shaped by the behavior you choose to train on.
This is why session construction matters more than trying every Word2Vec variant. If a user clicks product B after searching for dresses and then product C after searching for phones, putting B and C into the same context may teach the model the wrong thing. Airbnb’s definition of a new session after a 30-minute gap is not a universal rule, but it shows the kind of product judgment required.
Bookings as global context
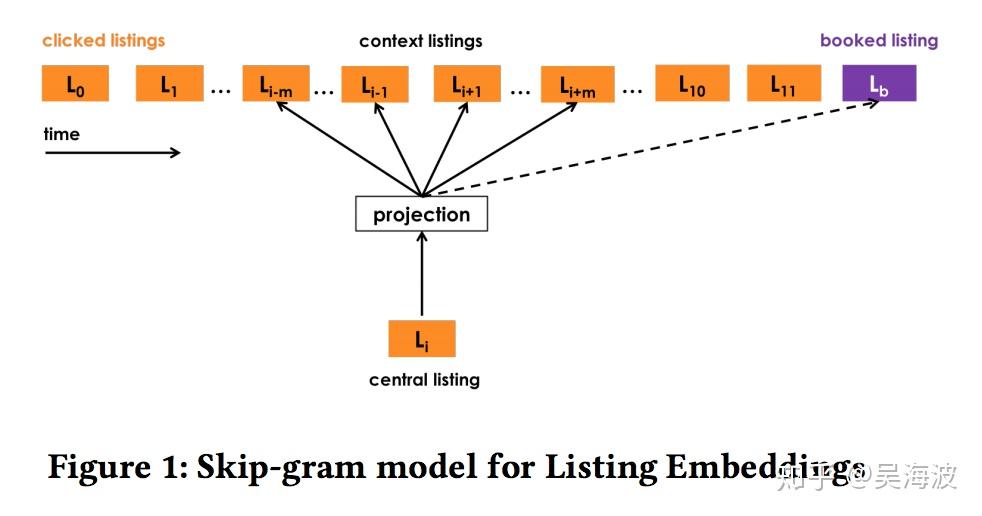
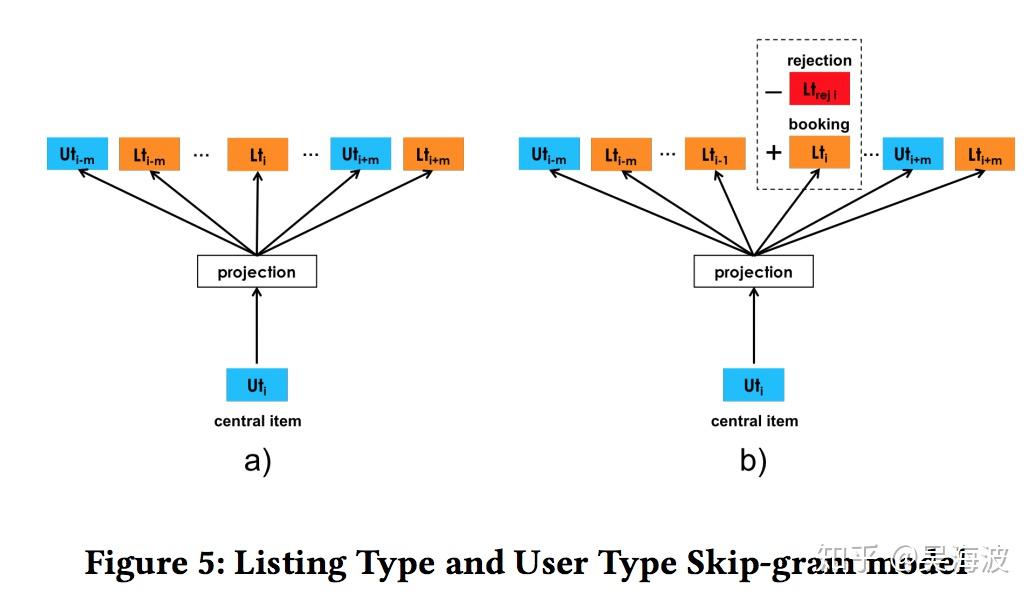
A nice part of the paper is the way booked listings are used as global context. A normal Word2Vec window changes as it slides through the session. Airbnb adds the eventually booked listing as a target that should be predicted regardless of whether it appears inside the local window.
Airbnb's adaptation adds the booked listing as global context.
My reading is that this is a simple way to move an unsupervised embedding objective closer to the business objective. It is not just learning what was nearby in behavior; it is also nudging the vector space toward what eventually converted.
The objective term that connects local behavior with the eventual booking.
Sparse IDs are still the hard part
Word2Vec is not magic. It still needs entities to appear often enough to learn useful representations. The real gain often comes from the middle-frequency items, not the head items or the long tail. Head items already have enough data for simpler item-to-item methods; tail items remain too sparse. A useful embedding system needs a large enough middle layer of entities.
Airbnb filters entities with roughly five to ten occurrences, and also uses clustering-like methods for sparse IDs. The specific rule is tied to Airbnb’s business, but the principle generalizes: if ID sparsity is not handled, the rest of the modeling discussion is premature.
A hashing example from the original discussion of sparse IDs.
From vectors to ranking features
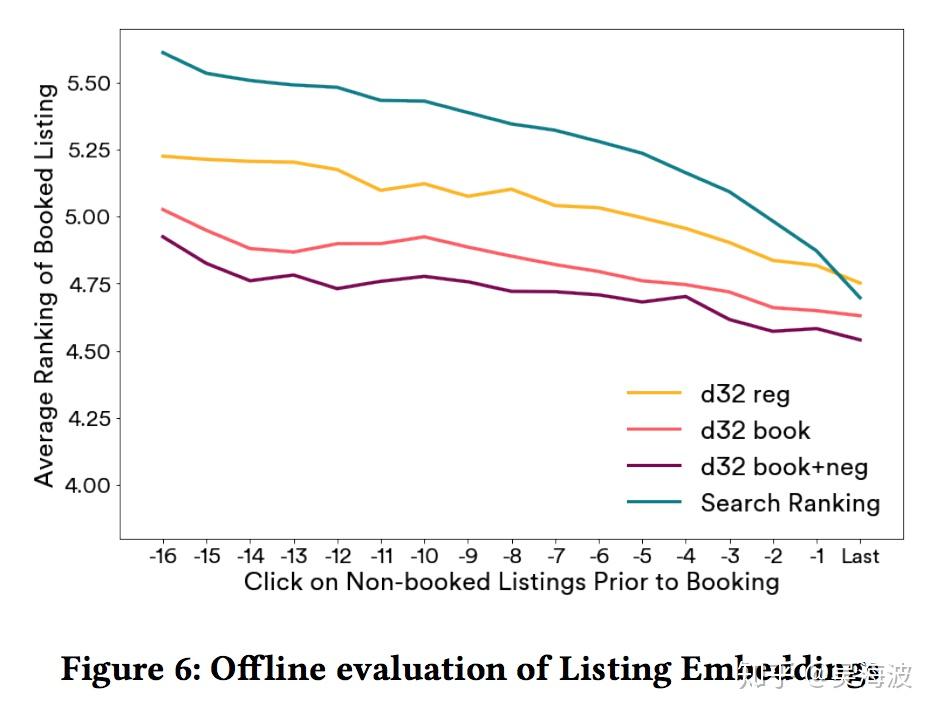
Real-time personalization itself is not mysterious once the behavior collection system exists. You can aggregate recent clicked listing embeddings, compare them with candidate listings through cosine similarity, and feed those similarities into the ranking model.
The paper is valuable because it makes the operational details concrete: short-term click embeddings, long-term booking signals, user-type and listing-type embeddings in the same vector space, daily training, offline vector evaluation, and online ranking experiments.
Offline ranking evaluation using embedding similarity. User-type and listing-type embeddings need to live in the same vector space.
The underused signal: negative feedback
Recommendation systems tend to overuse positive feedback: clicks, purchases, bookings. But negative feedback is important because one common user complaint is that personalization becomes a pile of similar content. Airbnb’s skipped listings and host rejections are interesting because they give the system a way to learn from what did not work.
In Mogujie’s scenario, we did not yet get clear gains from this kind of negative feedback, but the direction remains important. The paper is worth reading precisely because it is full of details that can be tried, questioned, and adapted in real systems.
Airbnb这篇论文拿了今年KDD best paper,和16年google的W&D类似,并不fancy,但非常practicable,值得一读。可喜的是,据我所知,国内一线团队的实践水平并不比论文中描述的差,而且就是W&D,国内也有团队在论文没有出来之前就做出了类似的结果,可见在推荐这样的场景,大家在一个水平线上。希望未来国内的公司,也发一些真正实用的paper,不一定非要去发听起来fancy的。
很多同学花很多时间在尝试各种word2vec的变种上,其实不如花时间在语料构建的细节上。首先,语料要多,论文中提到他们用了800 million search clicks sessions,在我们尝试Embedding的实践中,语料至少要过了亿级别才会发挥作用。其次,session的定义很重要。word2vec在计算词向量时和它context关系非常大,用户行为日志不像文本语料,存在标点符合、段落等标识去区分词的上下文。
Both are useful from the standpoint of capturing contextual similarity, however booked sessions can be used to adapt the optimization such that at each step we predict not only the neighboring clicked listings but the eventually booked listing as well. This adaptation can be achieved by adding booked listing as global context, such that it will always be predicted no matter if it is within the context window or not
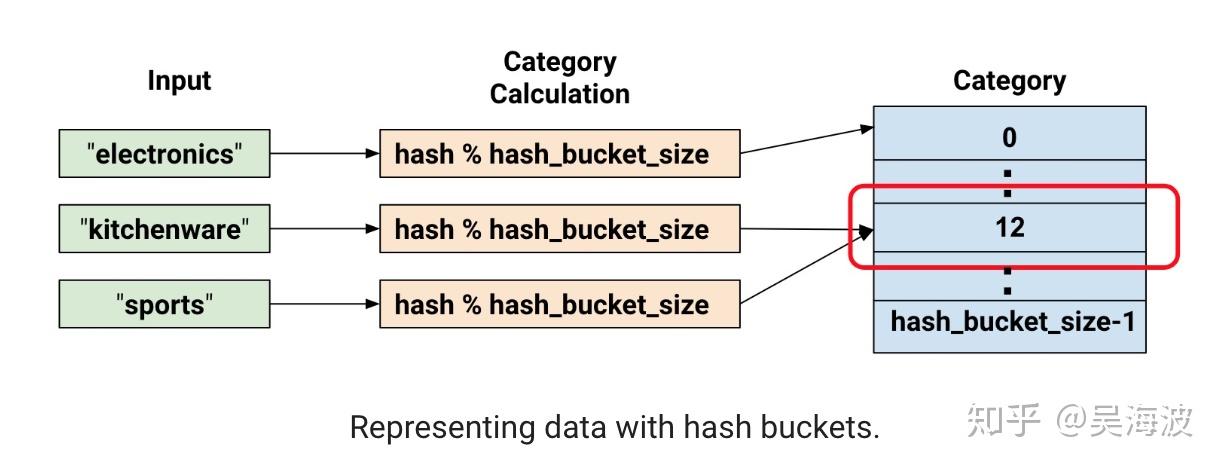
At this point, you might rightfully think: "This is crazy!" After all, we are forcing the different input values to a smaller set of categories. This means that two probably unrelated inputs will be mapped to the same category, and consequently mean the same thing to the neural network. The following figure illustrates this dilemma, showing that kitchenware and sports both get assigned to category (hash bucket) 12:
As with many counterintuitive phenomena in machine learning, it turns out that hashing often works well in practice. That's because hash categories provide the model with some separation. The model can use additional features to further separate kitchenware from sports.