After Claude Code's source leaked, I ran cloc and saw roughly 400,000 lines. I then asked Claude Code to look at the code with me. The conclusion was not that the core agent idea is complicated. It was that a production agent product contains a huge amount of surrounding engineering.
From the source, it is a full product-grade application: 40+ tool implementations with validation, permission models, progress tracking, and error handling; 140+ Ink/React terminal UI components; IDE bridge layers for VS Code and JetBrains; OAuth, JWT, macOS Keychain integration, organization policy controls; multi-agent coordination; plugin, skill, and memory systems; slash commands; session recovery; remote mode; voice input; Vim mode; themes; feature flags; telemetry; analytics; and a lot of TypeScript type definitions.
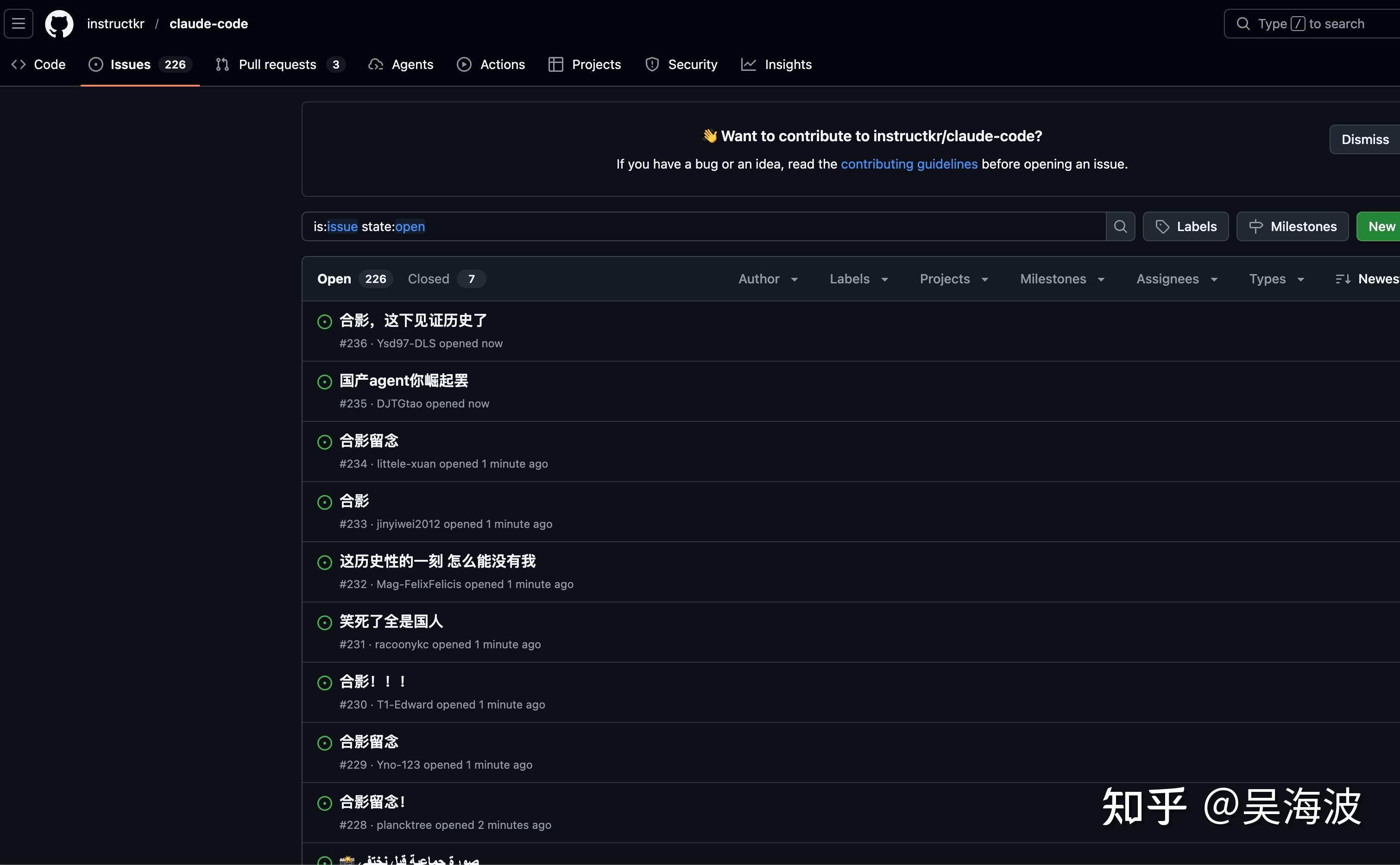
This probably explains why Claude Code can say it was built with Claude, while Anthropic is still hiring many engineers. AI can help write code, but real product engineering does not disappear.
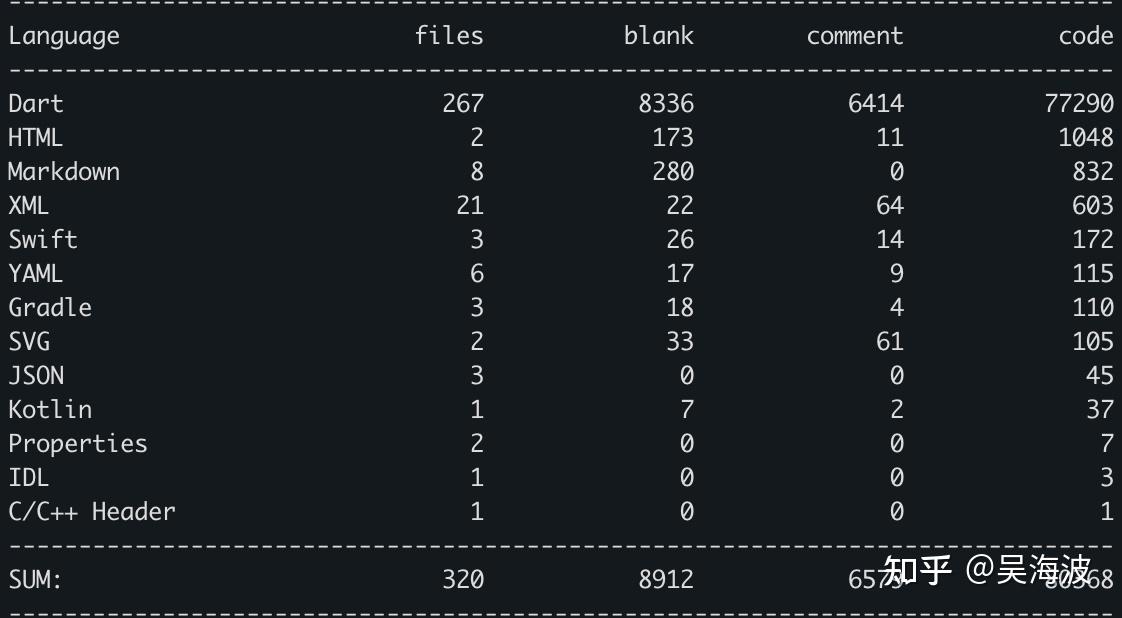
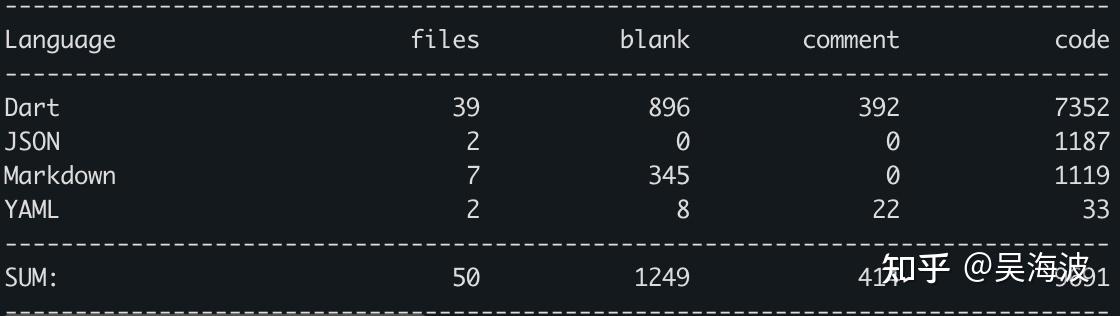
The core logic of an agent can indeed be a simple ReAct-style loop. But making that loop work in the real world requires a large amount of engineering. Since many answers focused on coding agents, I used our recent open-source personal-life-recording agent, Memex, as the example. Its agent logic runs locally on the phone, and the codebase had already grown to nearly 80,000 lines.
1. Connecting multiple LLM providers
OpenAI's API format is a de facto standard, but not every model provider or cloud vendor is fully compatible. To support multiple providers, you need wrappers for streaming output, token accounting, error handling, and edge cases.
Because the mobile Dart/Flutter ecosystem lacked a mature foundation for this, we open-sourced dart_agent_core to unify these interfaces. That layer alone reached around 7,000 lines.
2. Rebuilding the toolbox on mobile
Coding agents such as Devin can rely on a Linux shell and mature command-line tools. A phone does not have that environment. If an agent needs Grep, Find, or Edit-like capabilities, you have to implement those tool behaviors locally.
Memex also handles heterogeneous personal input: images, voice, and text. The agent needs to turn those fragments into structured markdown for management. We deliberately did not provide web search or generic HTTP tools. Memex is meant to focus on personal records and internal logic, not become a general-purpose OpenDevin-like system.
3. Knowledge management without simple RAG
Coding agents benefit from code's strong structure. Personal records are much messier, and simple retrieval-augmented generation is often not enough. We wrote substantial code and prompts to make the agent behave like a file manager: classifying, indexing, and organizing local records.
We also set strict read-write granularity limits for the knowledge base, so the agent cannot operate on huge files or directories at once and blow up the context. In some organization tasks, we add adversarial review logic: if the agent proposes a knowledge structure that violates rules, code checks reject it and ask the agent to redo the work.
4. Permissions and safety boundaries
An agent that can call tools and read memory is risky by default. Every tool call needs its own permission checks. The system also needs memory isolation: which data is visible to the agent, and how the agent verifies that it is not operating outside the intended boundary.
5. Engineering generative UI
We did not want the agent to output only text. Memex experiments with generative UI: a library of common app templates, plus a fallback path where the agent generates HTML and renders it in a WebView. The routing and rendering logic itself takes real engineering.
6. Process scheduling and state recovery on mobile
Mobile operating systems manage memory aggressively. The app process can be killed at any time. If an agent task is halfway done, the system has to save progress and recover instantly when the user reopens the app.
7. Observability for model calls
Agent execution produces many model calls. To make the system transparent and controllable, you need observability: how many calls a task used, how many tokens it spent, how much it cost, and where failures occurred.
You also need error tracking. If the agent enters a loop or produces invalid output, logs and automatic interception prevent wasted API spend and make debugging possible.
The core loop is the ideal. The tens of thousands of lines are reality: the code that lets the ideal survive real devices, real data, real users, and real failure modes.
Memex is still only an early prototype. If you are interested in this direction, the project is open at github.com/memex-lab/memex.